%load_ext autoreload
%autoreload 2Training Kalman Filter for Results
from meteo_imp.kalman.training import *
from meteo_imp.kalman.filter import *
from meteo_imp.utils import *
from meteo_imp.data import *
from meteo_imp.gaussian import *
from fastai.tabular.learner import *
from fastai.learner import *
from fastai.callback.all import *
from fastcore.foundation import L
from fastcore.foundation import patch
from pathlib import Path, PosixPath
from meteo_imp.kalman.training import show_results
import pandas as pd
import numpy as np
import torch
import random
from pyprojroot import here
from sklearn.decomposition import PCA
from matplotlib import pyplot as plt
from IPython.display import Image, HTML
from tqdm.auto import tqdmfrom fastcore.basics import *show_metrics = Falsereset_seed()hai = pd.read_parquet(hai_big_path)
hai_era = pd.read_parquet(hai_era_big_path)base = here("analysis/results/trained_models")base.mkdir(exist_ok=True)@patch
def add_end(self: PosixPath, end): return self.parent / (self.name + end)def train_or_load(model, dls, lr, n, path, keep=True):
save_models = SaveModelsBatch(times_epoch=5)
csv_logger = CSVLogger(path.add_end("log.csv"))
learn = Learner(dls, model, KalmanLoss(only_gap=True), cbs = [Float64Callback, save_models, csv_logger], metrics=rmse_gap)
items = random.choices(dls.valid.items, k=4)
if path.add_end(".pickle").exists() and keep:
learn.model = torch.load(path.add_end(".pickle"))
display(csv_logger.read_log())
plot = Image(filename=path.add_end("_loss_plot.png"))
display(plot)
else:
learn.fit(lr, n)
torch.save(learn.model, path.add_end(".pickle"))
learn.recorder.plot_loss()
plt.savefig(path.add_end("_loss_plot.png"))
return learn, items def metric_valid(learn, dls=None):
nrmse = []
losses = []
dls = ifnone(dls, learn.dls.valid)
for input, target in tqdm(dls, leave=False):
pred = learn.model(input)
nrmse.append(learn.metrics[0](pred, target))
losses.append(learn.loss_func(pred, target).item())
metric = pd.DataFrame({'loss': losses, 'rmse': nrmse})
return metric.agg(['mean', 'std'])hai.columnsIndex(['TA', 'SW_IN', 'LW_IN', 'VPD', 'WS', 'PA', 'P', 'SWC', 'TS'], dtype='object')Generic model | gap len 3-336 | gap 1 random
dls_A1v = imp_dataloader(
df = hai,
control = hai_era,
var_sel = gen_var_sel(list(hai.columns), n_var=1),
block_len=100+336,
gap_len=gen_gap_len(6, 336),
bs=20,
control_lags=[1],
shifts=gen_shifts(50),
n_rep=5).cpu()len(hai)227952len(dls_A1v.train)*20, len(dls_A1v.valid)*20(2080, 520)model_A1v = KalmanFilterSR.init_local_slope_pca(
n_dim_obs= len(hai.columns),
n_dim_state=len(hai.columns),
n_dim_contr = len(hai_era.columns),
df_pca = None,
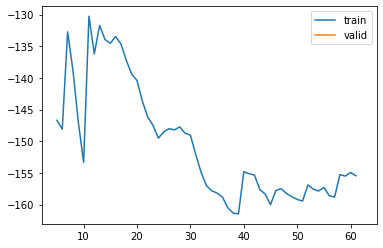
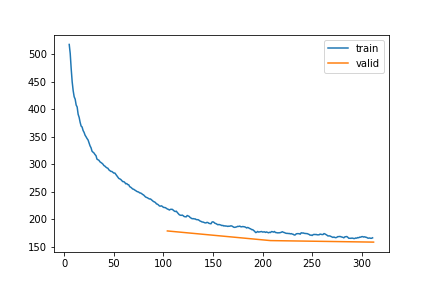
pred_only_gap=True)model_A1v.B.shapetorch.Size([1, 18, 14])learn_A1v, items_A1v = train_or_load(model_A1v, dls_A1v, 3, 1e-3, base / "1_gap_varying_6-336_v1")| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | 196.765350 | 163.493486 | 0.579074 | 48:33 |
| 1 | 1 | 138.298704 | 123.299909 | 0.490741 | 48:14 |
| 2 | 2 | 113.640141 | 116.746793 | 0.488059 | 39:00 |
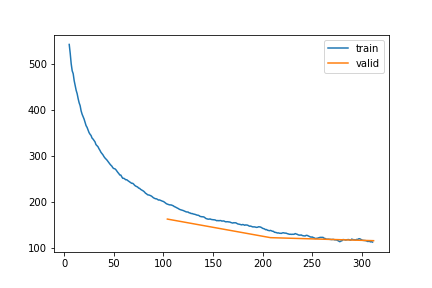
learn_A1v, items_A1v = train_or_load(model_A1v, dls_A1v, 1, 1e-4, base / "1_gap_varying_6-336_v2")| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | 94.869328 | 112.046392 | 0.471249 | 43:59 |
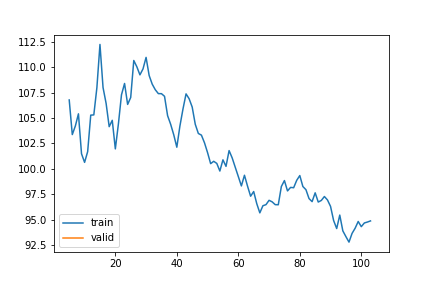
learn_A1v, items_A1v = train_or_load(model_A1v, dls_A1v, 1, 1e-6, base / "1_gap_varying_6-336_v3")| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | 95.239438 | 104.268073 | 0.467282 | 40:19 |
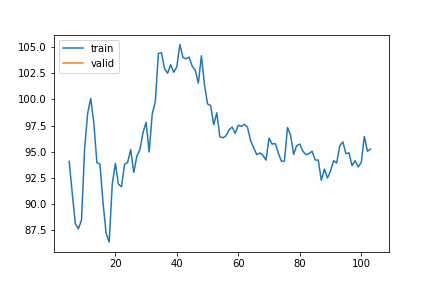
1 var gap - varying 336 - No Control
model_A1v_nc = KalmanFilterSR.init_local_slope_pca(
n_dim_obs= len(hai.columns),
n_dim_state=len(hai.columns),
n_dim_contr = len(hai_era.columns),
df_pca=None,
pred_only_gap=True,
use_control=False
)learn_A1v_nc, items_A1v_nc = train_or_load(model_A1v_nc, dls_A1v, 3, 1e-3, base / "1_gap_varying_336_no_control_v1")| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | 219.686355 | 178.506325 | 0.658579 | 37:14 |
| 1 | 1 | 176.039201 | 160.979378 | 0.583213 | 37:00 |
| 2 | 2 | 166.012525 | 158.206468 | 0.574111 | 36:47 |
Short gaps
All variables - 30 all
dls_Aa = imp_dataloader(
df = hai,
control = hai_era,
var_sel = list(hai.columns),
block_len=120,
gap_len=gen_gap_len(6, 30),
bs=20,
control_lags=[1],
shifts=gen_shifts(50),
n_rep=5
).cpu()dls_Aa = imp_dataloader(hai, hai_era, var_sel = list(hai.columns), block_len=120, gap_len=gen_gap_len(6,30), bs=20, control_lags=[1], n_rep=10).cpu()model_Aa = learn_A1v.model.copy()if show_metrics: display(metric_valid(learn_A1v, dls=dls_Aa.valid))dls_A1v30 = imp_dataloader(
df = hai,
control = hai_era,
var_sel = gen_var_sel(list(hai.columns), n_var=1),
block_len=100+30,
gap_len=gen_gap_len(6, 30),
bs=20,
control_lags=[1],
shifts=gen_shifts(50),
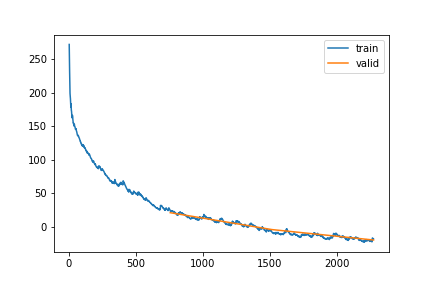
n_rep=5).cpu()if show_metrics: display(metric_valid(learn_A1v, dls=dls_A1v30.valid))learn_Aa, items_Aa = train_or_load(model_Aa, dls_Aa, 3, 3e-4, base / "All_gap_all_30_v1")| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | 24.688308 | 21.049544 | 0.365108 | 28:05 |
| 1 | 1 | -7.512621 | -4.152000 | 0.342344 | 27:26 |
| 2 | 2 | -18.230698 | -19.744404 | 0.327594 | 26:15 |
learn_A1v30, items_A1v30 = train_or_load(learn_A1v.model.copy(), dls_A1v30, 3, 3e-4, base / "1_gap_varying_tuned_6-30_v1")| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | 4.763339 | 3.134267 | 0.276432 | 15:02 |
| 1 | 1 | 2.390429 | 1.721823 | 0.267772 | 16:12 |
| 2 | 2 | 0.780169 | 0.607745 | 0.255524 | 16:05 |
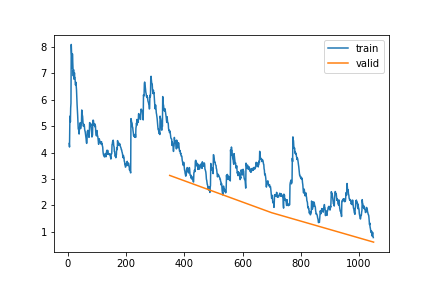
so this is not working …
Varying number of variables missing | short gaps 6-30
dls_Vv30 = imp_dataloader(
df = hai,
control = hai_era,
var_sel = gen_var_sel(list(hai.columns)),
block_len=100+30,
gap_len=gen_gap_len(6, 30),
bs=20,
control_lags=[1],
shifts=gen_shifts(50),
n_rep=20).cpu()learn_Vv30, items_Vv30 = train_or_load(learn_Aa.model, dls_Vv30, 3, 5e-4, base / "all_varying_gap_varying_len_6-30_v1")| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | -5.794561 | -4.508800 | 0.213908 | 1:00:55 |
| 1 | 1 | -3.717697 | -5.165062 | 0.205841 | 1:00:26 |
| 2 | 2 | -1.928287 | -6.012112 | 0.202048 | 1:00:21 |
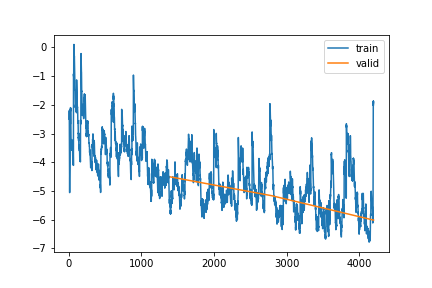
learn_Vv30, items_Vv30 = train_or_load(learn_Aa.model, dls_Vv30, 1, 1e-5, base / "all_varying_gap_varying_len_6-30_v2")| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | -7.061014 | -6.663726 | 0.192194 | 57:55 |
learn_Vv30, items_Vv30 = train_or_load(learn_Aa.model, dls_Vv30, 1, 1e-5, base / "all_varying_gap_varying_len_6-30_v3")| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | -7.417934 | -6.799482 | 0.19076 | 1:00:23 |
Random parameters
model_Vv_rand = KalmanFilterSR.init_random(
n_dim_obs= len(hai.columns),
n_dim_state=2*len(hai.columns),
n_dim_contr = 2*len(hai_era.columns),
seed=27,
pred_only_gap=True)learn_Vv_rand, items_Vv_rand = train_or_load(model_Vv_rand, dls_Vv30, 3, 1e-3, base / "rand_all_varying_gap_varying_len_6-30_v1")| epoch | train_loss | valid_loss | rmse_gap | time |
|---|---|---|---|---|
| 0 | 13.508053 | 14.374478 | 0.448185 | 1:00:35 |
| 1 | 9.766153 | 11.389963 | 0.395332 | 58:51 |
| 2 | 6.503961 | 6.754238 | 0.305433 | 54:16 |
learn_Vv_rand, items_Vv_rand = train_or_load(learn_Vv_rand.model, dls_Vv30, 3, 1e-4, base / "rand_all_varying_gap_varying_len_6-30_v2")| epoch | train_loss | valid_loss | rmse_gap | time |
|---|---|---|---|---|
| 0 | 5.101230 | 5.345336 | 0.285398 | 1:02:15 |
| 1 | 4.838514 | 4.907970 | 0.281667 | 1:02:44 |
| 2 | 4.571287 | 4.295109 | 0.275344 | 1:04:47 |
learn_Vv_rand, items_Vv_rand = train_or_load(learn_Vv_rand.model, dls_Vv30, 3, 1e-5, base / "rand_all_varying_gap_varying_len_6-30_v3")| epoch | train_loss | valid_loss | rmse_gap | time |
|---|---|---|---|---|
| 0 | 4.075190 | 4.282635 | 0.275272 | 2:36:25 |
| 1 | 5.134852 | 4.244826 | 0.274858 | 1:17:58 |
| 2 | 3.923739 | 4.185355 | 0.274057 | 1:11:31 |
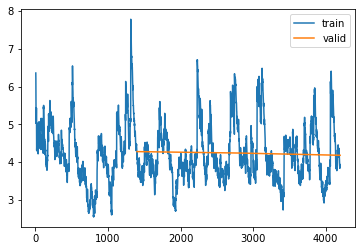
learn_Vv_rand, items_Vv_rand = train_or_load(learn_Vv_rand.model, dls_Vv30, 3, 1e-5, base / "rand_all_varying_gap_varying_len_6-30_v4")| epoch | train_loss | valid_loss | rmse_gap | time |
|---|---|---|---|---|
| 0 | 4.100049 | 4.142156 | 0.273928 | 56:48 |
| 1 | 3.712223 | 4.112651 | 0.273566 | 56:59 |
| 2 | 3.942678 | 4.073334 | 0.273349 | 57:03 |
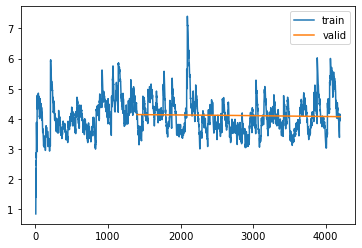
model_Vv_randKalman Filter (9 obs, 18 state, 14 contr)
$A$
| state | x_0 | x_1 | x_2 | x_3 | x_4 | x_5 | x_6 | x_7 | x_8 | x_9 | x_10 | x_11 | x_12 | x_13 | x_14 | x_15 | x_16 | x_17 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x_0 | 0.8775 | 0.2675 | 0.0937 | 0.6706 | 0.1638 | 0.9272 | 0.2620 | 0.4967 | 0.2630 | 0.1175 | 0.1694 | 0.2100 | 0.4890 | 0.0564 | 0.4760 | 0.7606 | 0.7759 | 0.5243 |
| x_1 | 0.3714 | 0.0426 | 0.2343 | 0.9991 | 0.1775 | 0.6319 | 0.6734 | 0.7937 | 0.6468 | 0.5825 | 0.4599 | 0.7960 | 0.9038 | 0.9735 | 0.6428 | 0.3725 | 0.2052 | 0.0507 |
| x_2 | 0.4448 | 0.5775 | 0.7237 | 0.5927 | 0.3217 | 0.6441 | 0.2801 | 0.9132 | 0.0329 | 0.4856 | 0.9927 | 0.5895 | 0.2611 | 0.9413 | 0.1371 | 0.8726 | 0.5590 | 0.8451 |
| x_3 | 0.1253 | 0.9434 | 0.0462 | 0.2360 | 0.0239 | 0.8950 | 0.7419 | 0.9471 | 0.6690 | 0.1554 | 0.0821 | 0.7309 | 0.7764 | 0.9769 | 0.0196 | 0.0384 | 0.4294 | 0.3438 |
| x_4 | 0.5494 | 0.8238 | 0.9845 | 0.6826 | 0.9001 | 0.3022 | 0.7509 | 0.0926 | 0.0328 | 0.4798 | 0.5335 | 0.0434 | 0.3530 | 0.4157 | 0.7495 | 0.1716 | 0.1980 | 0.4298 |
| x_5 | 0.9201 | 0.6883 | 0.5342 | 0.7847 | 0.3137 | 0.1778 | 0.5838 | 0.9799 | 0.3611 | 0.3155 | 0.7475 | 0.5450 | 0.5641 | 0.2493 | 0.8323 | 0.9723 | 0.1883 | 0.3605 |
| x_6 | 0.5344 | 0.3443 | 0.7696 | 0.3410 | 0.7553 | 0.3177 | 0.0315 | 0.5209 | 0.6514 | 0.3131 | 0.4510 | 0.3550 | 0.4790 | 0.0676 | 0.3606 | 0.7299 | 0.6713 | 0.3134 |
| x_7 | 0.7460 | 0.1291 | 0.4653 | 0.5693 | 0.9906 | 0.8288 | 0.9039 | 0.5240 | 0.6277 | 0.3574 | 0.0076 | 0.6530 | 0.8667 | 0.9368 | 0.8667 | 0.6749 | 0.3526 | 0.6618 |
| x_8 | 0.0837 | 0.7188 | 0.7247 | 0.3211 | 0.4898 | 0.9030 | 0.0358 | 0.1662 | 0.7741 | 0.7937 | 0.7183 | 0.5141 | 0.4918 | 0.2773 | 0.6901 | 0.8565 | 0.3723 | 0.3410 |
| x_9 | 0.4035 | 0.0591 | 0.6836 | 0.8306 | 0.4312 | 0.0210 | 0.0032 | 0.9010 | 0.6741 | 0.3875 | 0.3683 | 0.5337 | 0.0706 | 0.8516 | 0.7304 | 0.8507 | 0.6829 | 0.6900 |
| x_10 | 0.1059 | 0.0500 | 0.5736 | 0.9595 | 0.8101 | 0.7397 | 0.5282 | 0.1294 | 0.2746 | 0.5556 | 0.6463 | 0.0023 | 0.1761 | 0.3391 | 0.3346 | 0.4655 | 0.8172 | 0.4176 |
| x_11 | 0.1349 | 0.0519 | 0.1180 | 0.9767 | 0.1679 | 0.8635 | 0.3753 | 0.9760 | 0.2125 | 0.8049 | 0.2124 | 0.6794 | 0.0037 | 0.9711 | 0.5679 | 0.9474 | 0.8593 | 0.6385 |
| x_12 | 0.8770 | 0.0469 | 0.1582 | 0.6694 | 0.5670 | 0.9794 | 0.6498 | 0.3257 | 0.8462 | 0.7727 | 0.3213 | 0.7318 | 0.3665 | 0.9550 | 0.7188 | 0.2660 | 0.5867 | 0.1134 |
| x_13 | 0.7401 | 0.1982 | 0.4165 | 0.3814 | 0.5263 | 0.6516 | 0.9604 | 0.8996 | 0.8318 | 0.7448 | 0.6912 | 0.5938 | 0.0929 | 0.5298 | 0.2637 | 0.8722 | 0.5430 | 0.2217 |
| x_14 | 0.3495 | 0.3756 | 0.1251 | 0.4052 | 0.0638 | 0.0588 | 0.4379 | 0.4891 | 0.2796 | 0.0740 | 0.2123 | 0.1370 | 0.4477 | 0.3628 | 0.9125 | 0.4047 | 0.8130 | 0.2332 |
| x_15 | 0.8424 | 0.0816 | 0.8791 | 0.3892 | 0.2923 | 0.8603 | 0.1172 | 0.6212 | 0.6087 | 0.6072 | 0.8778 | 0.6758 | 0.5495 | 0.8240 | 0.7461 | 0.1555 | 0.2950 | 0.0365 |
| x_16 | 0.8060 | 0.8602 | 0.9453 | 0.7811 | 0.5495 | 0.5861 | 0.8480 | 0.1940 | 0.9206 | 0.5589 | 0.2148 | 0.1828 | 0.0636 | 0.2885 | 0.9426 | 0.6787 | 0.0080 | 0.7527 |
| x_17 | 0.5032 | 0.5585 | 0.0789 | 0.0409 | 0.3918 | 0.2908 | 0.3802 | 0.0407 | 0.6447 | 0.3241 | 0.8544 | 0.4245 | 0.3987 | 0.4367 | 0.3384 | 0.2285 | 0.7890 | 0.9094 |
$Q$
| state | x_0 | x_1 | x_2 | x_3 | x_4 | x_5 | x_6 | x_7 | x_8 | x_9 | x_10 | x_11 | x_12 | x_13 | x_14 | x_15 | x_16 | x_17 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x_0 | 1.4985 | 0.1823 | 0.8819 | 1.1215 | 0.8124 | 1.0154 | 0.4127 | 0.4993 | 0.3792 | 1.1249 | 0.3349 | 0.5480 | 1.1208 | 1.0406 | 0.0373 | 0.0713 | 0.0563 | 0.0038 |
| x_1 | 0.1823 | 0.7474 | 0.3388 | 0.8779 | 0.3284 | 0.4377 | 0.5683 | 0.6806 | 0.1517 | 0.6860 | 0.1334 | 0.2869 | 0.3903 | 0.5594 | 0.2687 | 0.7078 | 0.5301 | 0.5990 |
| x_2 | 0.8819 | 0.3388 | 1.5250 | 1.3832 | 1.4418 | 0.7184 | 0.4702 | 1.2013 | 1.1584 | 1.3029 | 1.0110 | 1.0116 | 1.4669 | 1.5483 | 0.6885 | 0.7897 | 1.0060 | 0.8858 |
| x_3 | 1.1215 | 0.8779 | 1.3832 | 2.4360 | 1.6422 | 1.2901 | 1.1545 | 1.7087 | 1.4626 | 2.4015 | 1.3411 | 1.4348 | 2.0194 | 2.1839 | 1.2870 | 1.3528 | 1.5829 | 1.6857 |
| x_4 | 0.8124 | 0.3284 | 1.4418 | 1.6422 | 3.2440 | 1.8293 | 0.6635 | 2.2540 | 1.7788 | 2.2643 | 1.5406 | 1.9412 | 2.5939 | 2.3073 | 2.1935 | 1.1262 | 1.5039 | 1.7599 |
| x_5 | 1.0154 | 0.4377 | 0.7184 | 1.2901 | 1.8293 | 2.6367 | 0.6717 | 2.0377 | 1.2394 | 1.6564 | 1.4530 | 1.5842 | 2.3638 | 2.1887 | 2.0828 | 1.2967 | 0.6836 | 0.8444 |
| x_6 | 0.4127 | 0.5683 | 0.4702 | 1.1545 | 0.6635 | 0.6717 | 1.8814 | 1.4915 | 0.6485 | 1.3643 | 0.6293 | 1.5192 | 1.1450 | 1.7599 | 1.6733 | 1.4465 | 0.7419 | 1.1889 |
| x_7 | 0.4993 | 0.6806 | 1.2013 | 1.7087 | 2.2540 | 2.0377 | 1.4915 | 3.7419 | 2.0936 | 2.3554 | 2.8167 | 2.9808 | 2.6624 | 3.4940 | 3.4288 | 2.7951 | 1.6056 | 2.6631 |
| x_8 | 0.3792 | 0.1517 | 1.1584 | 1.4626 | 1.7788 | 1.2394 | 0.6485 | 2.0936 | 3.2420 | 2.6115 | 2.9707 | 2.0584 | 3.2186 | 2.4394 | 2.7694 | 2.0308 | 2.6026 | 2.2404 |
| x_9 | 1.1249 | 0.6860 | 1.3029 | 2.4015 | 2.2643 | 1.6564 | 1.3643 | 2.3554 | 2.6115 | 4.7867 | 3.5267 | 2.4691 | 3.7434 | 3.6431 | 3.0501 | 2.1870 | 3.3714 | 2.4697 |
| x_10 | 0.3349 | 0.1334 | 1.0110 | 1.3411 | 1.5406 | 1.4530 | 0.6293 | 2.8167 | 2.9707 | 3.5267 | 4.8661 | 2.7361 | 3.9109 | 3.7590 | 4.1276 | 3.2131 | 3.3042 | 2.8676 |
| x_11 | 0.5480 | 0.2869 | 1.0116 | 1.4348 | 1.9412 | 1.5842 | 1.5192 | 2.9808 | 2.0584 | 2.4691 | 2.7361 | 4.5057 | 3.4122 | 4.2709 | 3.9642 | 3.3446 | 2.1979 | 2.7754 |
| x_12 | 1.1208 | 0.3903 | 1.4669 | 2.0194 | 2.5939 | 2.3638 | 1.1450 | 2.6624 | 3.2186 | 3.7434 | 3.9109 | 3.4122 | 6.2732 | 5.0000 | 5.0583 | 4.1123 | 3.9812 | 3.5458 |
| x_13 | 1.0406 | 0.5594 | 1.5483 | 2.1839 | 2.3073 | 2.1887 | 1.7599 | 3.4940 | 2.4394 | 3.6431 | 3.7590 | 4.2709 | 5.0000 | 6.2369 | 5.2005 | 4.6903 | 3.3753 | 4.1217 |
| x_14 | 0.0373 | 0.2687 | 0.6885 | 1.2870 | 2.1935 | 2.0828 | 1.6733 | 3.4288 | 2.7694 | 3.0501 | 4.1276 | 3.9642 | 5.0583 | 5.2005 | 7.8159 | 5.5318 | 4.1568 | 5.4245 |
| x_15 | 0.0713 | 0.7078 | 0.7897 | 1.3528 | 1.1262 | 1.2967 | 1.4465 | 2.7951 | 2.0308 | 2.1870 | 3.2131 | 3.3446 | 4.1123 | 4.6903 | 5.5318 | 5.8308 | 3.6118 | 5.0658 |
| x_16 | 0.0563 | 0.5301 | 1.0060 | 1.5829 | 1.5039 | 0.6836 | 0.7419 | 1.6056 | 2.6026 | 3.3714 | 3.3042 | 2.1979 | 3.9812 | 3.3753 | 4.1568 | 3.6118 | 5.2990 | 4.3170 |
| x_17 | 0.0038 | 0.5990 | 0.8858 | 1.6857 | 1.7599 | 0.8444 | 1.1889 | 2.6631 | 2.2404 | 2.4697 | 2.8676 | 2.7754 | 3.5458 | 4.1217 | 5.4245 | 5.0658 | 4.3170 | 7.1195 |
$b$
| state | offset |
|---|---|
| x_0 | 0.5371 |
| x_1 | 0.6015 |
| x_2 | 0.3190 |
| x_3 | 0.9543 |
| x_4 | 0.5112 |
| x_5 | 0.0341 |
| x_6 | 0.9601 |
| x_7 | 0.1604 |
| x_8 | 0.4499 |
| x_9 | 0.8575 |
| x_10 | 0.2647 |
| x_11 | 0.4293 |
| x_12 | 0.9210 |
| x_13 | 0.5512 |
| x_14 | 0.0890 |
| x_15 | 0.4351 |
| x_16 | 0.3804 |
| x_17 | 0.4879 |
$H$
| variable | x_0 | x_1 | x_2 | x_3 | x_4 | x_5 | x_6 | x_7 | x_8 | x_9 | x_10 | x_11 | x_12 | x_13 | x_14 | x_15 | x_16 | x_17 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| y_0 | 0.5241 | 0.2182 | 0.7958 | 0.7816 | 0.3235 | 0.8518 | 0.4334 | 0.7567 | 0.5235 | 0.2247 | 0.2498 | 0.6324 | 0.0037 | 0.8468 | 0.7664 | 0.0362 | 0.2519 | 0.5872 |
| y_1 | 0.4556 | 0.2781 | 0.0315 | 0.3598 | 0.2876 | 0.8363 | 0.0685 | 0.5543 | 0.9194 | 0.3232 | 0.0243 | 0.2689 | 0.8404 | 0.9788 | 0.9912 | 0.0846 | 0.1129 | 0.0503 |
| y_2 | 0.8881 | 0.6638 | 0.5292 | 0.3452 | 0.4999 | 0.6894 | 0.7628 | 0.4233 | 0.4219 | 0.3110 | 0.1801 | 0.5059 | 0.2597 | 0.9244 | 0.6246 | 0.8295 | 0.5742 | 0.7359 |
| y_3 | 0.2917 | 0.2912 | 0.9906 | 0.3964 | 0.5851 | 0.0647 | 0.3191 | 0.0659 | 0.9295 | 0.0189 | 0.8553 | 0.6701 | 0.6306 | 0.6152 | 0.5295 | 0.9469 | 0.9927 | 0.7433 |
| y_4 | 0.5977 | 0.7385 | 0.9348 | 0.8533 | 0.6523 | 0.7823 | 0.7676 | 0.4763 | 0.6374 | 0.8520 | 0.4391 | 0.5353 | 0.9097 | 0.7429 | 0.2067 | 0.4188 | 0.0382 | 0.9770 |
| y_5 | 0.6669 | 0.7935 | 0.4501 | 0.6770 | 0.0361 | 0.3082 | 0.9436 | 0.8420 | 0.2966 | 0.6996 | 0.8092 | 0.0206 | 0.9509 | 0.0499 | 0.3504 | 0.8491 | 0.5674 | 0.8691 |
| y_6 | 0.4429 | 0.2004 | 0.3868 | 0.9650 | 0.0220 | 0.4891 | 0.0179 | 0.3229 | 0.1670 | 0.6188 | 0.6477 | 0.0439 | 0.3738 | 0.3988 | 0.6175 | 0.9562 | 0.6395 | 0.7886 |
| y_7 | 0.6403 | 0.2487 | 0.6137 | 0.2387 | 0.7919 | 0.1610 | 0.2259 | 0.9336 | 0.8569 | 0.6710 | 0.9067 | 0.1028 | 0.7898 | 0.3126 | 0.5972 | 0.3078 | 0.3259 | 0.5631 |
| y_8 | 0.5374 | 0.9159 | 0.0255 | 0.7863 | 0.0953 | 0.7248 | 0.3355 | 0.1565 | 0.2010 | 0.3647 | 0.3080 | 0.8794 | 0.2877 | 0.2028 | 0.8040 | 0.8565 | 0.2100 | 0.2746 |
$R$
| variable | y_0 | y_1 | y_2 | y_3 | y_4 | y_5 | y_6 | y_7 | y_8 |
|---|---|---|---|---|---|---|---|---|---|
| y_0 | 0.5106 | 0.3847 | 0.4957 | 0.2641 | 0.0725 | 0.3685 | 0.7145 | 0.0334 | 0.6538 |
| y_1 | 0.3847 | 1.1931 | 1.0307 | 0.4238 | 0.1569 | 0.4712 | 0.6801 | 0.9019 | 0.7750 |
| y_2 | 0.4957 | 1.0307 | 1.9865 | 0.5453 | 0.3404 | 0.8202 | 1.0589 | 0.7202 | 1.1494 |
| y_3 | 0.2641 | 0.4238 | 0.5453 | 1.3356 | 0.2462 | 0.9538 | 0.8949 | 1.0863 | 1.4202 |
| y_4 | 0.0725 | 0.1569 | 0.3404 | 0.2462 | 0.9155 | 0.8953 | 0.5091 | 0.3793 | 0.3845 |
| y_5 | 0.3685 | 0.4712 | 0.8202 | 0.9538 | 0.8953 | 1.9467 | 1.7410 | 1.1834 | 1.4452 |
| y_6 | 0.7145 | 0.6801 | 1.0589 | 0.8949 | 0.5091 | 1.7410 | 2.9640 | 1.6060 | 1.6805 |
| y_7 | 0.0334 | 0.9019 | 0.7202 | 1.0863 | 0.3793 | 1.1834 | 1.6060 | 3.7560 | 2.1550 |
| y_8 | 0.6538 | 0.7750 | 1.1494 | 1.4202 | 0.3845 | 1.4452 | 1.6805 | 2.1550 | 3.0331 |
$d$
| variable | offset |
|---|---|
| y_0 | 0.4399 |
| y_1 | 0.8723 |
| y_2 | 0.2250 |
| y_3 | 0.0971 |
| y_4 | 0.6572 |
| y_5 | 0.7544 |
| y_6 | 0.5670 |
| y_7 | 0.7409 |
| y_8 | 0.7357 |
$B$
| state | c_0 | c_1 | c_2 | c_3 | c_4 | c_5 | c_6 | c_7 | c_8 | c_9 | c_10 | c_11 | c_12 | c_13 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x_0 | 0.0135 | 0.9418 | 0.6751 | 0.3042 | 0.0136 | 0.7803 | 0.2302 | 0.5920 | 0.7610 | 0.8504 | 0.2033 | 0.5990 | 0.8954 | 0.0604 |
| x_1 | 0.2530 | 0.1406 | 0.4280 | 0.1165 | 0.5817 | 0.2896 | 0.4509 | 0.2735 | 0.8425 | 0.5123 | 0.4176 | 0.5773 | 0.3222 | 0.5276 |
| x_2 | 0.4523 | 0.6324 | 0.4716 | 0.0785 | 0.9462 | 0.5346 | 0.9771 | 0.4970 | 0.5893 | 0.5292 | 0.6864 | 0.5196 | 0.8370 | 0.3849 |
| x_3 | 0.4922 | 0.3260 | 0.1990 | 0.6217 | 0.7287 | 0.4589 | 0.8500 | 0.1375 | 0.9457 | 0.8397 | 0.5203 | 0.8416 | 0.1371 | 0.5186 |
| x_4 | 0.4377 | 0.2392 | 0.4949 | 0.4146 | 0.3028 | 0.6810 | 0.1177 | 0.1563 | 0.2588 | 0.8996 | 0.9248 | 0.5575 | 0.2553 | 0.0631 |
| x_5 | 0.5413 | 0.5853 | 0.4166 | 0.9482 | 0.0665 | 0.4683 | 0.0348 | 0.6635 | 0.0501 | 0.1221 | 0.1268 | 0.7322 | 0.3311 | 0.0151 |
| x_6 | 0.1452 | 0.5820 | 0.8673 | 0.3090 | 0.8065 | 0.7325 | 0.1682 | 0.5885 | 0.1180 | 0.4120 | 0.2043 | 0.8200 | 0.5015 | 0.3238 |
| x_7 | 0.3842 | 0.4433 | 0.3052 | 0.4963 | 0.4459 | 0.9266 | 0.6286 | 0.8807 | 0.3252 | 0.0861 | 0.7891 | 0.1666 | 0.1766 | 0.0318 |
| x_8 | 0.8600 | 0.8088 | 0.8600 | 0.5418 | 0.4772 | 0.9634 | 0.3191 | 0.1484 | 0.6377 | 0.0586 | 0.5372 | 0.8380 | 0.8808 | 0.2243 |
| x_9 | 0.4277 | 0.0173 | 0.9436 | 0.3526 | 0.1852 | 0.2433 | 0.8409 | 0.7467 | 0.4969 | 0.2585 | 0.3466 | 0.4240 | 0.1253 | 0.2661 |
| x_10 | 0.9022 | 0.0314 | 0.0804 | 0.7244 | 0.3651 | 0.0938 | 0.8409 | 0.0069 | 0.3613 | 0.6663 | 0.1531 | 0.9582 | 0.1326 | 0.9434 |
| x_11 | 0.8686 | 0.9671 | 0.1879 | 0.7194 | 0.3153 | 0.5075 | 0.6469 | 0.0551 | 0.2449 | 0.5830 | 0.3328 | 0.4071 | 0.2686 | 0.4456 |
| x_12 | 0.5746 | 0.1570 | 0.5606 | 0.7224 | 0.6012 | 0.4299 | 0.0548 | 0.3849 | 0.0750 | 0.4321 | 0.9120 | 0.4023 | 0.5149 | 0.5738 |
| x_13 | 0.1813 | 0.1437 | 0.8099 | 0.2174 | 0.2784 | 0.7365 | 0.5066 | 0.1417 | 0.6935 | 0.0812 | 0.0792 | 0.1286 | 0.6698 | 0.1731 |
| x_14 | 0.3023 | 0.8685 | 0.0737 | 0.2969 | 0.0566 | 0.7863 | 0.9368 | 0.2227 | 0.0272 | 0.9288 | 0.2405 | 0.8415 | 0.4647 | 0.5220 |
| x_15 | 0.2359 | 0.5393 | 0.3662 | 0.9737 | 0.1073 | 0.0926 | 0.9738 | 0.8049 | 0.2272 | 0.4266 | 0.4965 | 0.2811 | 0.5143 | 0.1134 |
| x_16 | 0.8076 | 0.4430 | 0.9223 | 0.0757 | 0.7333 | 0.1208 | 0.4115 | 0.5446 | 0.8064 | 0.5765 | 0.2153 | 0.4235 | 0.2613 | 0.2662 |
| x_17 | 0.4906 | 0.6666 | 0.1782 | 0.4631 | 0.4471 | 0.4886 | 0.6511 | 0.1357 | 0.9547 | 0.8251 | 0.5739 | 0.0537 | 0.9671 | 0.1413 |
$m_0$
| state | mean |
|---|---|
| x_0 | 0.4748 |
| x_1 | 0.0525 |
| x_2 | 0.8524 |
| x_3 | 0.5821 |
| x_4 | 0.7281 |
| x_5 | 0.9879 |
| x_6 | 0.6011 |
| x_7 | 0.4692 |
| x_8 | 0.9031 |
| x_9 | 0.9123 |
| x_10 | 0.6185 |
| x_11 | 0.8070 |
| x_12 | 0.5830 |
| x_13 | 0.5986 |
| x_14 | 0.5898 |
| x_15 | 0.8722 |
| x_16 | 0.7868 |
| x_17 | 0.8305 |
$P_0$
| state | x_0 | x_1 | x_2 | x_3 | x_4 | x_5 | x_6 | x_7 | x_8 | x_9 | x_10 | x_11 | x_12 | x_13 | x_14 | x_15 | x_16 | x_17 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x_0 | 0.7075 | 0.4575 | 0.1025 | 0.7552 | 0.4678 | 0.4102 | 0.6403 | 0.2264 | 0.0279 | 0.6776 | 0.8178 | 0.4180 | 0.7019 | 0.4730 | 0.7924 | 0.5532 | 0.6499 | 0.0084 |
| x_1 | 0.4575 | 1.3349 | 0.8975 | 1.0693 | 0.9878 | 0.5854 | 0.6734 | 0.6813 | 0.5162 | 1.2483 | 1.1523 | 0.6240 | 0.8392 | 0.6469 | 1.1093 | 0.4286 | 0.6817 | 0.5511 |
| x_2 | 0.1025 | 0.8975 | 1.7778 | 1.4223 | 1.0713 | 0.5301 | 0.4902 | 0.9565 | 0.7575 | 1.1096 | 0.6516 | 0.6540 | 1.3722 | 0.9620 | 0.6709 | 1.0418 | 0.7424 | 0.5799 |
| x_3 | 0.7552 | 1.0693 | 1.4223 | 2.9851 | 1.4541 | 1.0645 | 1.6541 | 0.9605 | 1.5344 | 2.4493 | 1.9649 | 1.5684 | 1.7126 | 1.3214 | 1.6471 | 1.7876 | 1.5110 | 1.4273 |
| x_4 | 0.4678 | 0.9878 | 1.0713 | 1.4541 | 1.6513 | 1.2777 | 1.3102 | 0.7676 | 1.0484 | 1.4509 | 1.6367 | 1.4200 | 1.9104 | 0.8253 | 1.1014 | 0.9313 | 1.6568 | 1.2782 |
| x_5 | 0.4102 | 0.5854 | 0.5301 | 1.0645 | 1.2777 | 2.0910 | 2.0046 | 1.1160 | 1.0262 | 1.7268 | 2.2526 | 2.0053 | 2.1983 | 1.2724 | 1.6174 | 1.5978 | 2.3012 | 1.8972 |
| x_6 | 0.6403 | 0.6734 | 0.4902 | 1.6541 | 1.3102 | 2.0046 | 3.2961 | 1.3658 | 2.1582 | 2.6066 | 2.7869 | 2.4754 | 2.3180 | 1.8782 | 1.9604 | 2.2224 | 3.0209 | 2.9851 |
| x_7 | 0.2264 | 0.6813 | 0.9565 | 0.9605 | 0.7676 | 1.1160 | 1.3658 | 2.2370 | 1.1397 | 2.0217 | 1.7425 | 1.4582 | 1.7065 | 1.2660 | 1.8500 | 1.3857 | 2.3256 | 1.4360 |
| x_8 | 0.0279 | 0.5162 | 0.7575 | 1.5344 | 1.0484 | 1.0262 | 2.1582 | 1.1397 | 3.1976 | 2.4686 | 2.6294 | 2.0770 | 2.1077 | 1.4005 | 1.6343 | 2.0925 | 2.2970 | 2.9207 |
| x_9 | 0.6776 | 1.2483 | 1.1096 | 2.4493 | 1.4509 | 1.7268 | 2.6066 | 2.0217 | 2.4686 | 3.8815 | 3.3607 | 2.4745 | 3.0405 | 2.4247 | 2.8433 | 3.0134 | 3.4315 | 3.3814 |
| x_10 | 0.8178 | 1.1523 | 0.6516 | 1.9649 | 1.6367 | 2.2526 | 2.7869 | 1.7425 | 2.6294 | 3.3607 | 4.7920 | 3.0654 | 3.5766 | 2.7664 | 3.4915 | 3.4792 | 4.0401 | 3.2582 |
| x_11 | 0.4180 | 0.6240 | 0.6540 | 1.5684 | 1.4200 | 2.0053 | 2.4754 | 1.4582 | 2.0770 | 2.4745 | 3.0654 | 3.1407 | 3.3492 | 2.5045 | 2.9033 | 2.5216 | 3.3064 | 2.7858 |
| x_12 | 0.7019 | 0.8392 | 1.3722 | 1.7126 | 1.9104 | 2.1983 | 2.3180 | 1.7065 | 2.1077 | 3.0405 | 3.5766 | 3.3492 | 6.7801 | 4.6939 | 3.9369 | 4.9600 | 4.8216 | 3.7575 |
| x_13 | 0.4730 | 0.6469 | 0.9620 | 1.3214 | 0.8253 | 1.2724 | 1.8782 | 1.2660 | 1.4005 | 2.4247 | 2.7664 | 2.5045 | 4.6939 | 5.2116 | 3.8491 | 4.6837 | 3.8005 | 3.5731 |
| x_14 | 0.7924 | 1.1093 | 0.6709 | 1.6471 | 1.1014 | 1.6174 | 1.9604 | 1.8500 | 1.6343 | 2.8433 | 3.4915 | 2.9033 | 3.9369 | 3.8491 | 5.2003 | 4.0112 | 3.8169 | 3.0359 |
| x_15 | 0.5532 | 0.4286 | 1.0418 | 1.7876 | 0.9313 | 1.5978 | 2.2224 | 1.3857 | 2.0925 | 3.0134 | 3.4792 | 2.5216 | 4.9600 | 4.6837 | 4.0112 | 6.7694 | 5.0850 | 4.5844 |
| x_16 | 0.6499 | 0.6817 | 0.7424 | 1.5110 | 1.6568 | 2.3012 | 3.0209 | 2.3256 | 2.2970 | 3.4315 | 4.0401 | 3.3064 | 4.8216 | 3.8005 | 3.8169 | 5.0850 | 6.7135 | 5.3989 |
| x_17 | 0.0084 | 0.5511 | 0.5799 | 1.4273 | 1.2782 | 1.8972 | 2.9851 | 1.4360 | 2.9207 | 3.3814 | 3.2582 | 2.7858 | 3.7575 | 3.5731 | 3.0359 | 4.5844 | 5.3989 | 7.9999 |
Fine tuning
Fine tune Variable | gap only for one variable | gap len 6-336
fine tune the model to only one variable
from fastcore.basics import *from IPython.display import HTMLvar_learning = {
'TA': [{'lr': 1e-3, 'n': 3}],
'SW_IN': [{'lr': 1e-3, 'n': 4}],
'SW_IN': [{'lr': 1e-3, 'n': 4}],
'LW_IN': [{'lr': 1e-3, 'n': 3}],
'VPD': [{'lr': 1e-3, 'n': 3}],
'WS': [{'lr': 1e-3, 'n': 3}],
'PA': [{'lr': 1e-3, 'n': 3}],
# 'P': [{'lr': 1e-3, 'n': 3}], missing on purpose
'SWC' : [{'lr': 1e-3, 'n': 5}, {'lr': 1e-5, 'n': 1}],
'TS' : [{'lr': 1e-3, 'n': 5}],
}/home/simone/anaconda3/envs/data-science/lib/python3.10/site-packages/fastai/callback/core.py:69: UserWarning: You are shadowing an attribute (__class__) that exists in the learner. Use `self.learn.__class__` to avoid this
warn(f"You are shadowing an attribute ({name}) that exists in the learner. Use `self.learn.{name}` to avoid this")def fine_tune(var_learning, learn):
spec_models = {}
spec_dls = {}
spec_learn = {}
spec_items = {}
for var in tqdm(var_learning.keys()):
display(HTML(f"<h4> {var} | Gap len 6-336 finetune</h4>"))
spec_dls[var] = imp_dataloader(hai, hai_era, var_sel = var, block_len=100+336, gap_len=gen_gap_len(6, 336), bs=20, control_lags=[1], n_rep=3, shifts=gen_shifts(50)).cpu()
if show_metrics:
display(HTML("Metrics generic model"))
display(metric_valid(learn, dls=spec_dls[var].valid))
for i, train in enumerate(var_learning[var]):
lr, n = train
display(HTML(f"train {i}"))
spec_models[var] = learn.model.copy()
spec_learn[var], spec_items[var] = train_or_load(spec_models[var], spec_dls[var], lr, n, base / f"{var}_specialized_gap_6-336_v1_{i}")
plt.show()
return spec_models, spec_dls, spec_learn, spec_itemsspec_models, spec_dls, spec_learn, spec_items = fine_tune(var_learning, learn_A1v)TA | Gap len 6-336 finetune
train 0
| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | -73.308072 | -59.729135 | 0.155103 | 23:04 |
| 1 | 1 | -87.049737 | -73.262853 | 0.139768 | 20:37 |
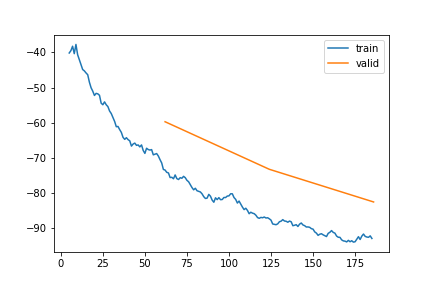
| 2 | 2 | -92.947376 | -82.557740 | 0.131374 | 21:16 |
SW_IN | Gap len 6-336 finetune
train 0
| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | 53.445060 | 43.464660 | 0.286705 | 23:25 |
| 1 | 1 | 49.458273 | 42.814378 | 0.285042 | 23:47 |
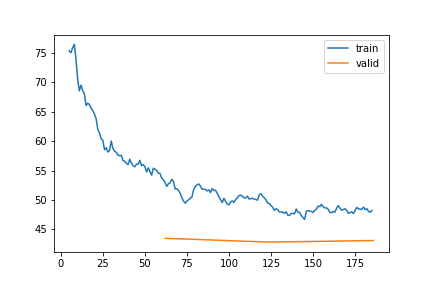
| 2 | 2 | 48.186476 | 43.087234 | 0.283170 | 22:43 |
LW_IN | Gap len 6-336 finetune
train 0
| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | 104.665918 | 106.041969 | 0.414556 | 22:34 |
| 1 | 1 | 101.284686 | 107.526856 | 0.419593 | 23:28 |
| 2 | 2 | 99.767878 | 108.885340 | 0.420613 | 23:43 |
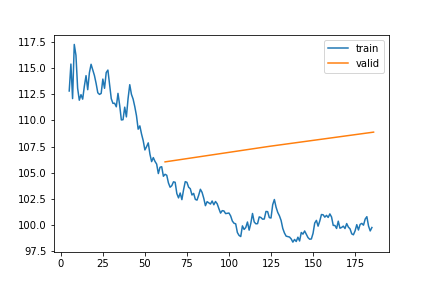
VPD | Gap len 6-336 finetune
train 0
| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | 52.165032 | 50.852617 | 0.295505 | 23:31 |
| 1 | 1 | 45.131744 | 36.635116 | 0.272213 | 22:41 |
| 2 | 2 | 41.990330 | 32.914802 | 0.264974 | 23:06 |
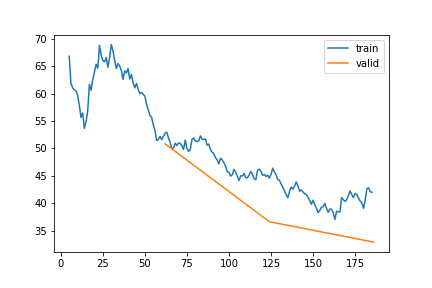
WS | Gap len 6-336 finetune
train 0
| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | 175.891940 | 246.176982 | 0.761467 | 22:58 |
| 1 | 1 | 165.224262 | 235.823659 | 0.719208 | 23:03 |
| 2 | 2 | 159.586716 | 246.720599 | 0.727202 | 21:00 |
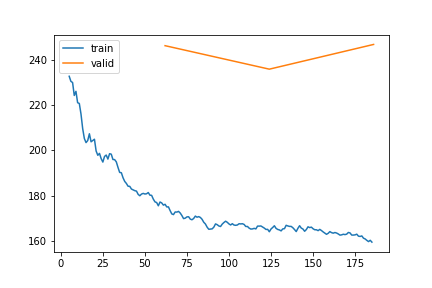
PA | Gap len 6-336 finetune
train 0
| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | -99.014311 | -97.738537 | 0.127062 | 21:53 |
| 1 | 1 | -123.031773 | -104.182228 | 0.120468 | 22:45 |
| 2 | 2 | -130.901483 | -133.160406 | 0.104076 | 24:11 |
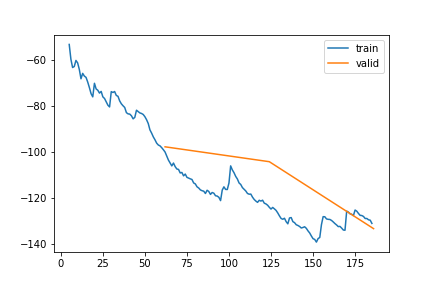
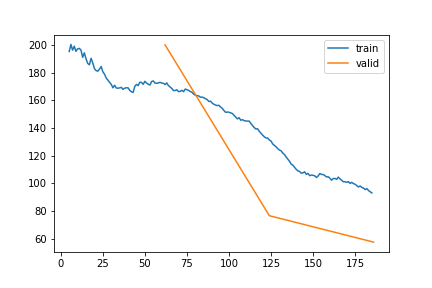
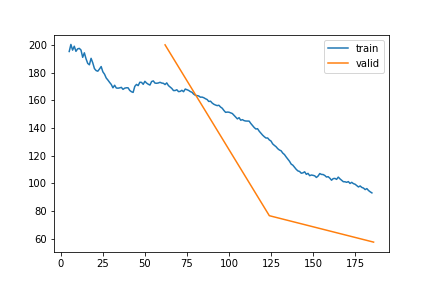
SWC | Gap len 6-336 finetune
train 0
| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | 172.303569 | 200.127139 | 0.599423 | 23:57 |
| 1 | 1 | 132.754943 | 76.512459 | 0.305065 | 22:01 |
| 2 | 2 | 93.005439 | 57.391193 | 0.270830 | 20:58 |
train 1
| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | 172.303569 | 200.127139 | 0.599423 | 23:57 |
| 1 | 1 | 132.754943 | 76.512459 | 0.305065 | 22:01 |
| 2 | 2 | 93.005439 | 57.391193 | 0.270830 | 20:58 |
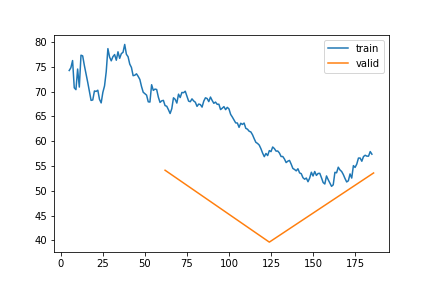
TS | Gap len 6-336 finetune
train 0
| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | 68.246805 | 54.157492 | 0.268725 | 23:05 |
| 1 | 1 | 57.107431 | 39.662085 | 0.247396 | 21:34 |
| 2 | 2 | 57.394308 | 53.605346 | 0.260903 | 20:52 |
var_learning2 = {
'TA': [{'lr': 1e-3, 'n': 3}],
'VPD': [{'lr': 1e-3, 'n': 2}],
'PA': [{'lr': 1e-3, 'n': 2}],
'SWC' : [{'lr': 1e-3, 'n': 3}, {'lr': 1e-5, 'n': 1}],
'TS' : [{'lr': 1e-3, 'n': 2}],
}def fine_tune2(var_learning, spec_dls, spec_learn, spec_items):
spec_learn = spec_learn.copy()
for var in tqdm(var_learning.keys()):
display(HTML(f"<h4> {var} | Gap len 6-336 finetune 2 </h4>"))
for i, train in enumerate(var_learning[var]):
lr, n = train['lr'], train['n']
v = train.get('v', 2)
display(HTML(f"train {i}"))
spec_learn[var], _ = train_or_load(spec_learn[var].model, spec_dls[var], n, lr, path=base / f"{var}_specialized_gap_6-336_v{v}_{i}")
plt.show()
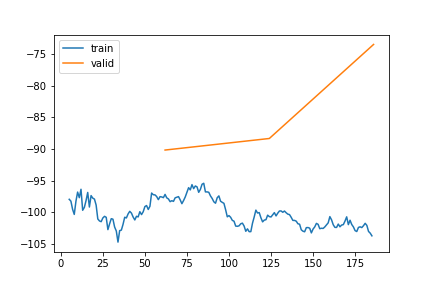
return spec_dls, spec_learn, spec_itemsspec_dls2, spec_learn2, spec_items2 = fine_tune2(var_learning2, spec_dls, spec_learn, spec_items)TA | Gap len 6-336 finetune 2
train 0
| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | -97.718002 | -90.171141 | 0.125761 | 21:44 |
| 1 | 1 | -100.493585 | -88.338616 | 0.126856 | 20:23 |
| 2 | 2 | -103.769092 | -73.432097 | 0.135440 | 20:41 |
SW_IN | Gap len 6-336 finetune 2
train 0
| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | 45.373127 | 42.291928 | 0.282366 | 20:34 |
| 1 | 1 | 46.487908 | 41.780965 | 0.283791 | 20:26 |
| 2 | 2 | 46.903155 | 45.729009 | 0.290985 | 20:43 |
| 3 | 3 | 46.917554 | 39.832071 | 0.278899 | 20:29 |
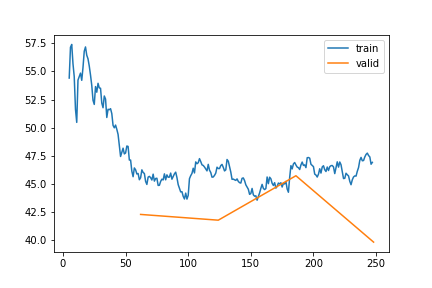
LW_IN | Gap len 6-336 finetune 2
train 0
| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | 98.188426 | 107.646729 | 0.414824 | 20:22 |
| 1 | 1 | 95.761911 | 108.694974 | 0.416340 | 20:30 |
| 2 | 2 | 97.285924 | 106.717304 | 0.415862 | 20:30 |
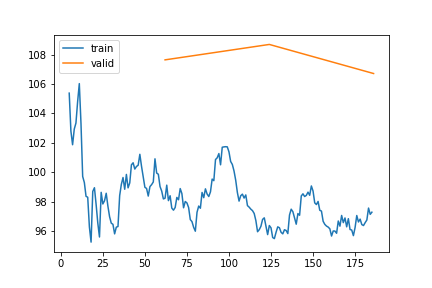
VPD | Gap len 6-336 finetune 2
train 0
| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | 42.370522 | 31.185345 | 0.254092 | 20:27 |
| 1 | 1 | 37.933048 | 29.823322 | 0.255506 | 20:25 |
| 2 | 2 | 35.904875 | 25.101849 | 0.245977 | 20:28 |
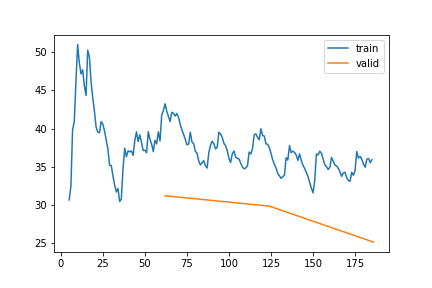
WS | Gap len 6-336 finetune 2
train 0
| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | 158.971839 | 247.131486 | 0.730278 | 20:37 |
| 1 | 1 | 158.584698 | 253.701959 | 0.736434 | 20:34 |
| 2 | 2 | 156.970299 | 263.529629 | 0.749744 | 20:22 |
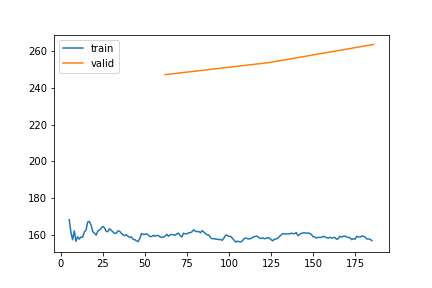
PA | Gap len 6-336 finetune 2
train 0
| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | -131.680055 | -112.508634 | 0.115626 | 23:56 |
| 1 | 1 | -145.849450 | -95.348580 | 0.114896 | 24:38 |
| 2 | 2 | -145.281960 | -107.879192 | 0.116886 | 24:47 |
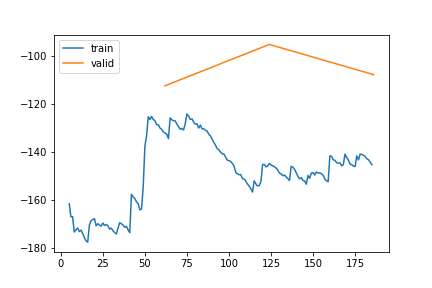
SWC | Gap len 6-336 finetune 2
train 0
| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | 35.588624 | -20.680066 | 0.174256 | 24:56 |
| 1 | 1 | 10.683595 | -23.630941 | 0.167582 | 24:32 |
| 2 | 2 | -34.885516 | -76.834793 | 0.124991 | 25:11 |
| 3 | 3 | -47.704883 | 0.936394 | 0.166095 | 24:47 |
| 4 | 4 | -61.871826 | -75.499625 | 0.120001 | 24:45 |
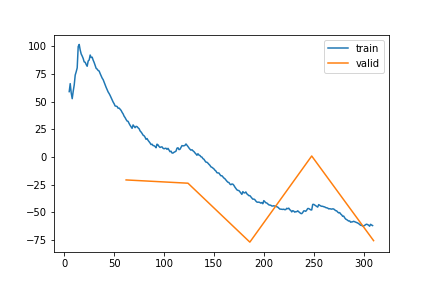
train 1
| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | -82.762576 | -101.858651 | 0.103941 | 24:41 |
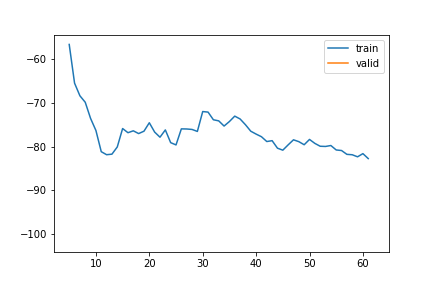
TS | Gap len 6-336 finetune 2
train 0
| epoch | train_loss | valid_loss | rmse_gap | time | |
|---|---|---|---|---|---|
| 0 | 0 | 40.478151 | 29.605951 | 0.230160 | 25:47 |
| 1 | 1 | 36.143091 | 21.822619 | 0.211396 | 28:18 |
| 2 | 2 | 30.493916 | -0.701642 | 0.181059 | 24:59 |
| 3 | 3 | 26.646244 | 17.138843 | 0.201734 | 27:48 |
| 4 | 4 | 19.231903 | 10.231487 | 0.202251 | 29:09 |
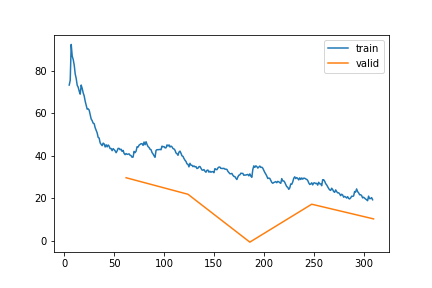
var_learning3 = {
'TA': [{'lr': 1e-5, 'n': 1, 'v': 3}],
'PA': [{'lr': 1e-5, 'n': 1, 'v': 3}],
}spec_dls3, spec_learn3, spec_items3 = fine_tune2(var_learning3, spec_dls, spec_learn, spec_items)TA | Gap len 6-336 finetune 2
train 0
| epoch | train_loss | valid_loss | rmse_gap | time |
|---|---|---|---|---|
| 0 | -98.172894 | -86.769272 | 0.131181 | 28:21 |
PA | Gap len 6-336 finetune 2
train 0
| epoch | train_loss | valid_loss | rmse_gap | time |
|---|---|---|---|---|
| 0 | -155.452174 | -135.116148 | 0.105047 | 27:51 |